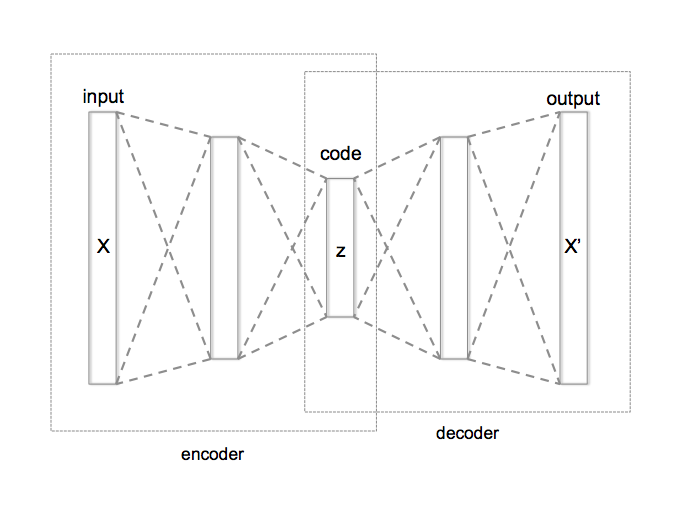
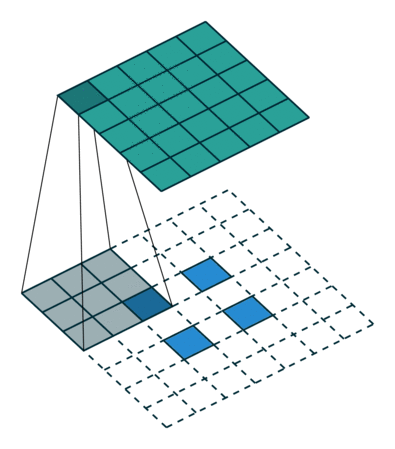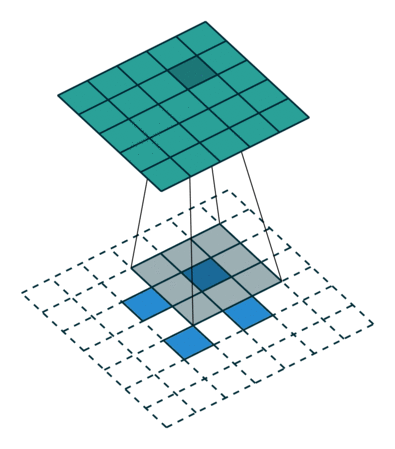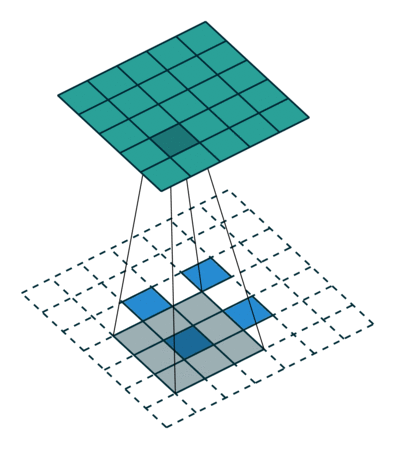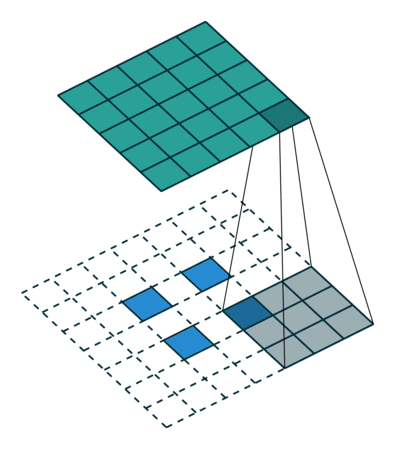
ENCODING_DIM = 256
input_layer = tf.keras.layers.Input(shape=(128, 128, 3))
encoder = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), strides=2, padding='same')(input_layer)
encoder = tf.keras.layers.LeakyReLU(alpha=0.2)(encoder)
encoder = tf.keras.layers.BatchNormalization()(encoder)
encoder = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), strides=2, padding='same')(encoder)
encoder = tf.keras.layers.LeakyReLU(alpha=0.2)(encoder)
encoder = tf.keras.layers.BatchNormalization()(encoder)
encoder_output_shape = encoder.shape
encoder = tf.keras.layers.Flatten()(encoder)
encoder_output = tf.keras.layers.Dense(ENCODING_DIM)(encoder)
encoder_model = tf.keras.models.Model(inputs=input_layer, outputs=encoder_output)
decoder_input = tf.keras.layers.Input(shape=(ENCODING_DIM,))
target_shape = tuple(encoder_output_shape[1:])
decoder = tf.keras.layers.Dense(np.prod(target_shape))(decoder_input)
decoder = tf.keras.layers.Reshape(target_shape)(decoder)
decoder = tf.keras.layers.Conv2DTranspose(filters=64, kernel_size=(3, 3), strides=2, padding='same')(decoder)
decoder = tf.keras.layers.LeakyReLU(alpha=0.2)(decoder)
decoder = tf.keras.layers.BatchNormalization()(decoder)
decoder = tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=(3, 3), strides=2, padding='same')(decoder)
decoder = tf.keras.layers.LeakyReLU(alpha=0.2)(decoder)
decoder = tf.keras.layers.BatchNormalization()(decoder)
decoder = tf.keras.layers.Conv2DTranspose(filters=3, kernel_size=(3, 3), padding='same')(decoder)
outputs = tf.keras.layers.Activation('sigmoid')(decoder)
decoder_model = tf.keras.models.Model(inputs=decoder_input, outputs=outputs)
encoder_model_outputs = encoder_model(input_layer)
decoder_model_outputs = decoder_model(encoder_model_outputs)
autoencoder_model = tf.keras.models.Model(inputs=input_layer, outputs=decoder_model_outputs)
autoencoder_model.compile(optimizer='adam', loss='mse')
|