Do you agree that dealing with large data file is such a painful task? If yes, then you shouldn't ignore this post! In this post, I'll show you which is the best storage format to work with if you are using Pandas. Is it csv, hdf5 or parquet? Let's find out.
First of all, we import some python packages that we will use in this benchmark
from pathlib import Pathimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport randomimport stringresutls = {}
Let's define this function to generate random data
def generate_test_data (nrows=10000 , numerical_cols=2000 , text_cols=0 , text_length=10 ): s = "" .join([random.choice(string.ascii_letters) for _ in range (text_length)]) data = pd.concat([pd.DataFrame(np.random.random(size=(nrows, numerical_cols))), pd.DataFrame(np.full(shape=(nrows, text_cols), fill_value=s))], axis=1 , ignore_index=True ) data.columns = [str (i) for i in data.columns] return data
1. Mixed Data Type
The first benchmark uses data that contains both text and numeric values.
1.1. Generate test data
Now generate 50,000 rows, 1000 cols (500 is numerical, 500 is text)
> df = generate_test_data(nrows=50000 , numerical_cols=500 , text_cols=500 ) > df.info() <class 'pandas .core .frame .DataFrame '> RangeIndex :50000 entries, 0 to 49999 Columns: 1000 entries, 0 to 999 dtypes: float64(500 ), object (500 ) memory usage: 381.5 + MB
1.2. Parquet
parquet_file = Path('test.parquet' )
File Size
df.to_parquet(parquet_file) size = parquet_file.stat().st_size
Read
%%timeit -o df = pd.read_parquet(parquet_file)
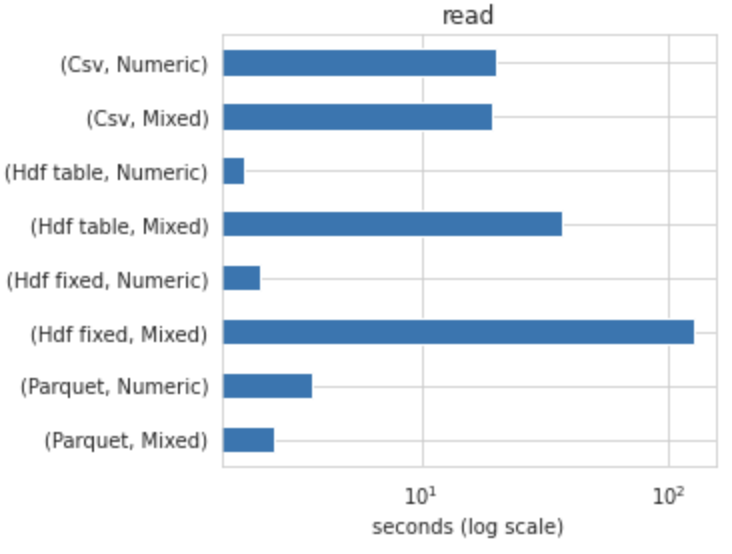
2.54 s ± 137 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
read = _ parquet_file.unlink()
Write
%%timeit -o df.to_parquet(parquet_file) parquet_file.unlink()
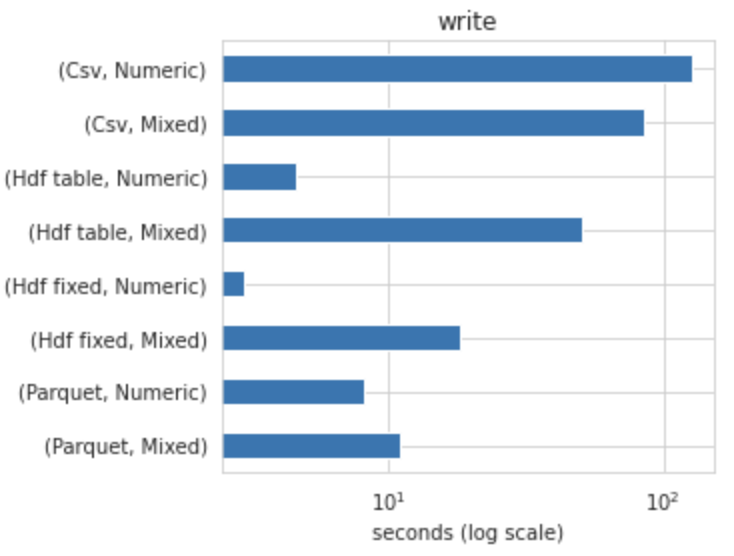
11.1 s ± 154 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Results
results['Parquet' ] = { 'read' : np.mean(read.all_runs), 'write' : np.mean(write.all_runs), 'size' : size}
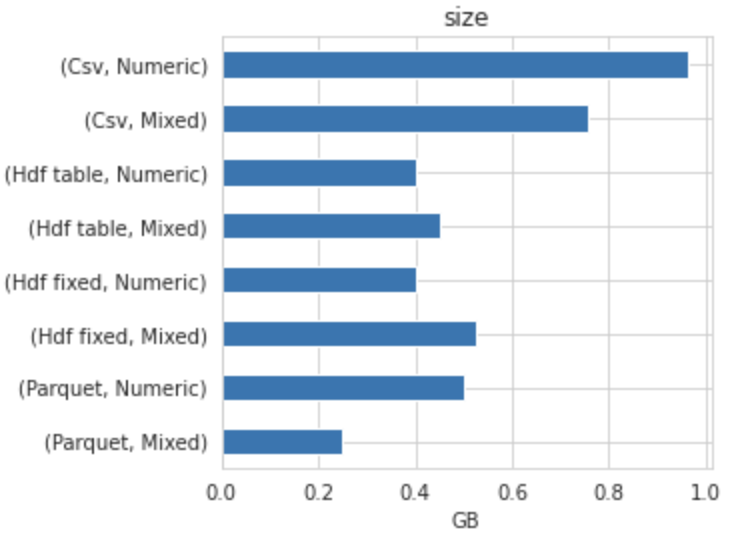
{'Parquet' : {'read' : 2.5449909000002924 , 'write' : 11.076020042857376 , 'size' : 250677616 }}
1.3. HDF5
test_store = Path('index.h5' )
Support fast writing/reading. Not-appendable, nor searchable.
File Size
with pd.HDFStore(test_store) as store: store.put('file' , df) size = test_store.stat().st_size
Read
%%timeit -o with pd.HDFStore(test_store) as store: store.get('file' )
2min 6s ± 1.41 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
read = _ test_store.unlink()
Write
%%timeit -r 1 -o with pd.HDFStore(test_store) as store: store.put('file' , df) test_store.unlink()
18.1 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
Results
results['HDF Fixed' ] = { 'read' : np.mean(read.all_runs), 'write' : np.mean(write.all_runs), 'size' : size}
{'Parquet' : {'read' : 2.5449909000002924 , 'write' : 11.076020042857376 , 'size' : 250677616 }, 'HDF Fixed' : {'read' : 126.0261167285714 , 'write' : 18.103147300000273 , 'size' : 526559612 }}
Write as a PyTables Table structure which may perform worse but allow more flexible operations like searching / selecting subsets of the data.
File Size
with pd.HDFStore(test_store) as store: store.append('file' , df, format ='t' ) size = test_store.stat().st_size
Read
%%timeit -o with pd.HDFStore(test_store) as store: df = store.get('file' )
36.9 s ± 174 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
read = _ test_store.unlink()
Write
Note that write in table format does not work with text data.
%%timeit -r 1 -o with pd.HDFStore(test_store) as store: store.append('file' , df, format ='t' ) test_store.unlink()
50.7 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
Results
results['HDF Table' ] = {'read' : np.mean(read.all_runs), 'write' : np.mean(write.all_runs), 'size' : size}
{'Parquet' : {'read' : 2.5449909000002924 , 'write' : 11.076020042857376 , 'size' : 250677616 }, 'HDF Fixed' : {'read' : 126.0261167285714 , 'write' : 18.103147300000273 , 'size' : 526559612 }, 'HDF Table' : {'read' : 36.89537138571411 , 'write' : 50.74519110000074 , 'size' : 450753287 }}
1.4. CSV
test_csv = Path('test.csv' )
File Size
df.to_csv(test_csv) test_csv.stat().st_size
Read
%%timeit -o df = pd.read_csv(test_csv)
19.2 s ± 642 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
read = _ test_csv.unlink()
Write
%%timeit -o df.to_csv(test_csv) test_csv.unlink()
1min 25s ± 307 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Results
results['CSV' ] = {'read' : np.mean(read.all_runs), 'write' : np.mean(write.all_runs), 'size' : size}
{'Parquet' : {'read' : 2.5449909000002924 , 'write' : 11.076020042857376 , 'size' : 250677616 }, 'HDF Fixed' : {'read' : 126.0261167285714 , 'write' : 18.103147300000273 , 'size' : 526559612 }, 'HDF Table' : {'read' : 36.89537138571411 , 'write' : 50.74519110000074 , 'size' : 450753287 }, 'CSV' : {'read' : 19.198365685714375 , 'write' : 85.28064355714274 , 'size' : 757038275 }}
1.5. Save the results
pd.DataFrame(results).assign(Data='Mixed' ).to_csv(f'Mixed.csv' )
2. Numeric Data Type
The second benchmark uses only numeric data types.
2.1. Generate test data
Now generate 50,000 rows, 1000 numeric cols
> df = generate_test_data(nrows=50000 , numerical_cols=1000 , text_cols=0 ) > df.info() <class 'pandas .core .frame .DataFrame '> RangeIndex :50000 entries, 0 to 49999 Columns: 1000 entries, 0 to 999 dtypes: float64(1000 ) memory usage: 381.5 MB
2.2. Parquet
Similar to 1.2
Results
{'Parquet' : {'read' : 3.6358330142858386 , 'write' : 8.220626242857179 , 'size' : 500764950 }}
2.3. HDFS
Similar to 1.3.1
Results
{'Parquet' : {'read' : 3.6358330142858386 , 'write' : 8.220626242857179 , 'size' : 500764950 }, 'HDF Fixed' : {'read' : 2.215434942857038 , 'write' : 2.988903299999947 , 'size' : 400411192 }}
Similar to 1.3.2
Results
{'Parquet' : {'read' : 3.6358330142858386 , 'write' : 8.220626242857179 , 'size' : 500764950 }, 'HDF Fixed' : {'read' : 2.215434942857038 , 'write' : 2.988903299999947 , 'size' : 400411192 }, 'HDF Table' : {'read' : 1.9255916428573983 , 'write' : 4.61305960000027 , 'size' : 400649196 }}
2.4. CSV
Similar to 1.4
Results
{'Parquet' : {'read' : 3.6358330142858386 , 'write' : 8.220626242857179 , 'size' : 500764950 }, 'HDF Fixed' : {'read' : 2.215434942857038 , 'write' : 2.988903299999947 , 'size' : 400411192 }, 'HDF Table' : {'read' : 1.9255916428573983 , 'write' : 4.61305960000027 , 'size' : 400649196 }, 'CSV' : {'read' : 19.857885385714585 , 'write' : 126.95752420000021 , 'size' : 963788438 }}
3. Results
3.1. Visualization
Read
Write
File Size
3.2. So what?
Parquet is the best option if your data is mixed.HDF5 if your data only contains numeric data type.